2019年08月23日の午後から、インターネット界隈ではある種のお祭りのような出来事がありました。
「AWSの障害によるさまざまなサービスが使えなくなった」
Twitterでもすごい勢いで皆さん反応されてましたね。
ゲームアプリにも影響が及んでいたため、あなたも影響を受けたのではないでしょうか。

IT関連の知識がない人には、「AWS障害」というキーワードが独り歩きしているような状態だと思います。
この記事では、あまり知識がない人向けに次のことをお話しします。
- AWSとは何なのか
- どんな事が起こったのか
- どの程度の影響があったのか
- クラウドサービスの是非
あの日に何があったのか、知りたい方はぜひ一読ください。
もくじ
そもそもAWSって何?→Amazonのクラウドサービス
AWSとはAmazon Web Serviceの略です。
サーバやデータベースなどを、アマゾンのクラウドプラットフォーム上で構築・運用できるITインフラストラクチャサービスのことです。
2006年から運用を開始し、日本でも有名な企業の多くが利用しています。
従来のITシステムは、データセンターと呼ばれるサーバなどを集めた場所で、企業毎に物理的なサーバを管理していました。
AWSを利用することで、物理サーバーを企業毎に用意する必要がなくなります。
管理やコスト面で従来のITシステム構築よりもメリットが多いため、現在ではAWSへ移行する企業が多くなっています。
AWS障害の原因
AWS障害の原因は、冷却システムの故障によるサーバの加熱で物理的に問題が起きたことでした。
当時の公式メッセージは、現在確認できないのでまとめサイト参照→piyolog
日本の中にあるAvailability Zone:AZ(アベイラビリティゾーン)の障害です。
AZは、端的に言えばデータセンターのことを表します。
AZの中にサーバやデータベースがあるので、アプリやWebサービスが使えなくなっていたんですね。
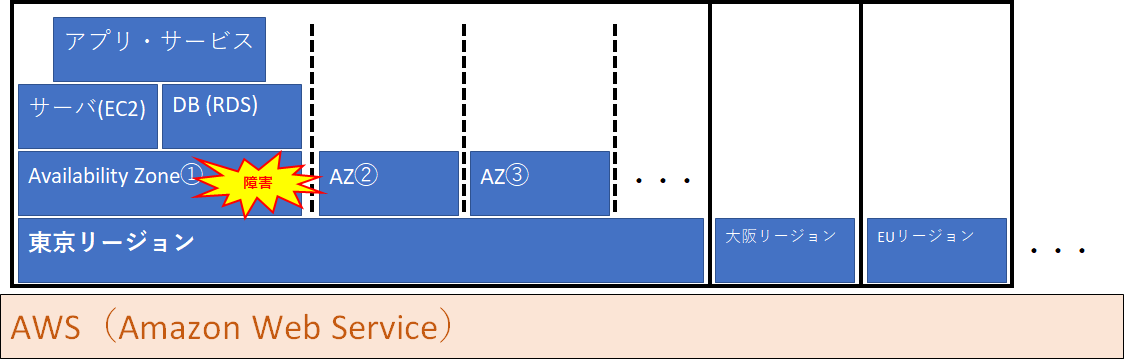
AWSをざっくりと図解
影響を受けたWebサービスやアプリなど
ほんの一部だけ紹介すると、次のようなサービスが使えなくなっていました。
- PayPay
- ラクマ
- Hulu
- パズル&ドラゴンズ
- メイプルストーリーM
などなど
その時のユーザーはこんな感じ。
まだ落ちてるんかい! #パズドラ これ本当に #AWS障害 のせい?怪しくなってきたな。。。
— ちゅら藻 (@Mr_churamo) August 23, 2019
ドスパラからシステム障害のお詫びメールが来ていたがAWS使ってるのだろうか?
ドスパラファイト!!#AWS障害— しんや (@shinya_k_777) August 23, 2019
昨日からスパロボDD始めたんですが、さっきアクセスしたらメンテ中でこんなのが。。AWSっておもっくそかいとるー。 #スパロボDD #AWS障害 pic.twitter.com/xwDKnutlye
— タタ @ロマサガRS楽しい勢 (@Rakkobe) August 23, 2019
一般ユーザーは、主にゲーム関連で不都合が発生していたように思えます。
企業のインフラ担当者は、気が気でなかったでしょう。
クラウドはダメだ!→違う
Twitterを眺めていると、「クラウドはやっぱりダメだ」という意見もちらほら見かけます。
しかし、一概にそうとは言えないでしょう。
その理由について書いていきます。
AZは分けることが基本(Multi-AZ)
今回の障害は、特定のAZで起きた問題です。
AWSでサーバを構築する場合、複数のAZに分けて構築することが基本となります。
これはAWSに限った話ではなく、ITシステムのインフラ設計として、一部の障害でシステム全体が使えないようにならないための対処法です。
本来は、一部のAZで障害が発生したとしても、問題がないようにMulti-AZで対応しているはずです。
今回の障害に巻き込まれた企業の中には、コストの問題などからシングルAZで運用していた例もあるでしょう。
とはいえ、マルチAZでもダメだった説
障害の影響を受けた企業は数多く、そのすべての企業がシングルAZだったのかと言われると、違うでしょう。
マルチAZにすることは、サービスを提供するが分からしたら基本的なことなので、むしろ対応していない企業は少ないのでは...?
そこで、こんなツイートを見かけました。
今回のAWS障害の影響マトリクスです
【影響を受けた勢】
マルチAZにしてた+apne1-az4を踏んでた
シングルAZだった+apne1-az4を踏んでた【影響を受けなかった勢】
マルチAZにしてた+apne1-az4を踏んでなかった
シングルAZだった+apne1-az4を踏んでなかった— 伊藤 祐策(パソコンの大先生) (@ito_yusaku) August 23, 2019
マルチAZにしていても、今回障害のあったAZを含んでいた場合は障害を回避できなかった、というお話。

と聞こえてきそうですが、マルチAZ以外にも、マルチリージョンにする方法もあります。
今回の障害は東京リージョンでしたので、別のリージョンにサーバを置いておけば回避できますね。
要は、AWSが全般的に悪いということではなく、設計側にも非があるということを認めないといけないということです。
AWSも責任範囲については明記していますからね。

どんなに便利で、多くの企業が使っているプラットフォームだとしても、障害に対する備えは万全にしなければならない、と考えます。
まとめ:Amazonだって万能ではない
GAFAの一角をなすAmazonですが、もちろん万能ではありません。
データセンターがぶっ壊れて数時間で直す、という対応をしただけでも、Amazonはすごいと思いますが。
今回の障害は、各企業のITインフラを見直すきっかけになったのではないでしょうか。
エンドユーザーの皆様におかれましては、現在のITインフラの状況を確認するきっかけとなったでしょう。
サービスが使えなくなって、いろいろと不便を感じたと思いますが、中の人達はがんばっています。